Biography
I am a fifth year Ph.D. student at Tsinghua University, advised by Prof. Gao Huang and Prof. Cheng Wu. My research interests lie in the model architecuture design, graph neural network and 3D computer vision.
I’m on job market now! If you are interested in me, contact me via Email.
Download my resumé (CN/EN).
Interests
- Machine Learning
- Computer Vision
Education
-
Ph.D. in Automation, 2018-Present
Tsinghua University
-
BSc in Automation, 2014-2018
Tsinghua University
Recent News
2023-03 One paper accepted by CVPR 2023 !
2023-01 One paper accepted by ICLR 2023 !
2022-09 One paper accepted by NeurIPS 2022 !
Selected Publications
Publications
Quickly discover relevant content by filtering publications.
(2023).
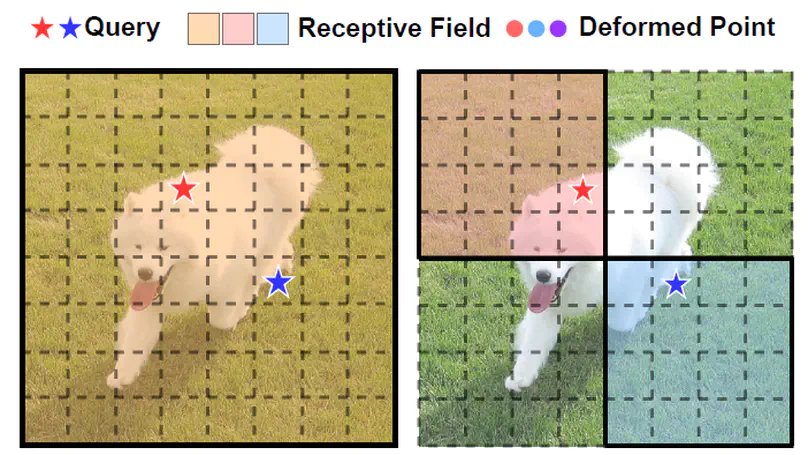
Slide-Transformer: Hierarchical Vision Transformer with Local Self-Attention.
In Computer Vision and Pattern Recognition (CVPR) 2023.
(2023).
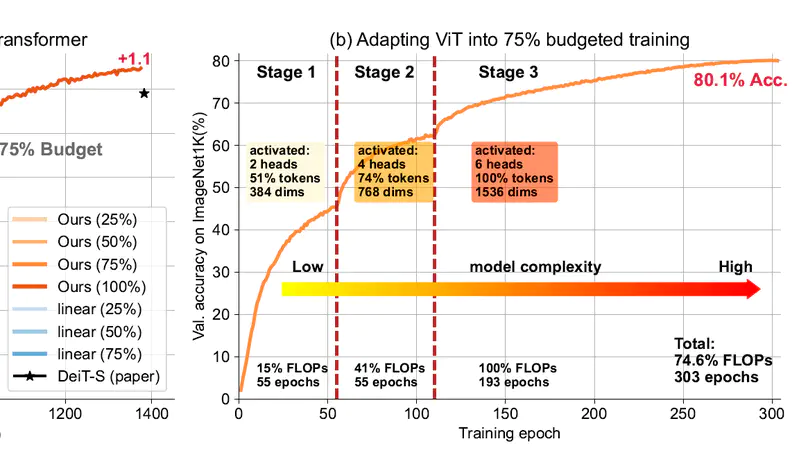
Budgeted Training for Vision Transformer.
In International Conference on Learning Representation (ICLR) 2023.
(2022).
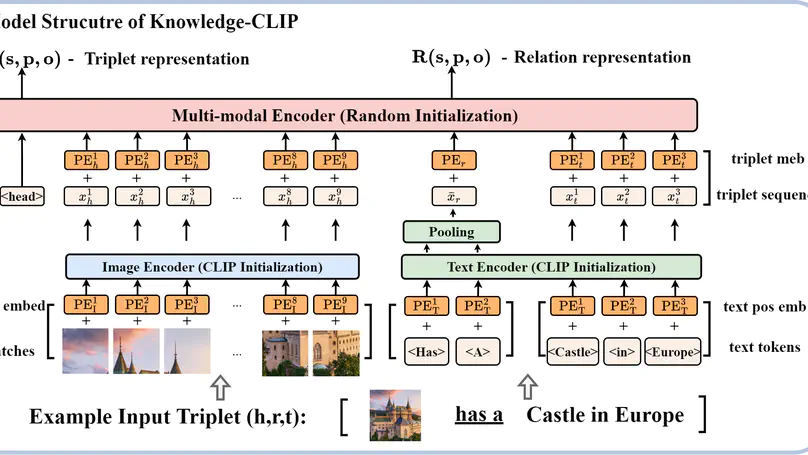
Contrastive Language-Image Pre-Training with Knowledge Graphs.
In Neural Information Processing Systems (NeurIPS) 2022.
(2022).
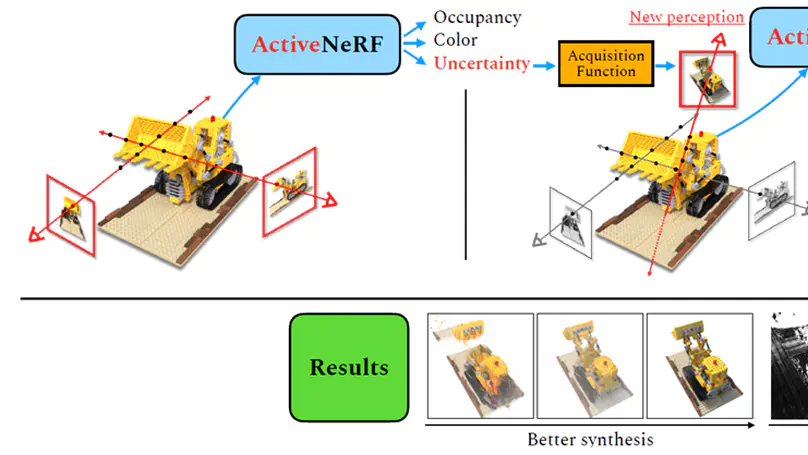
ActiveNeRF: Learning where to See with Uncertainty Estimation.
In European Conference on Computer Vision (ECCV) 2022.
(2022).
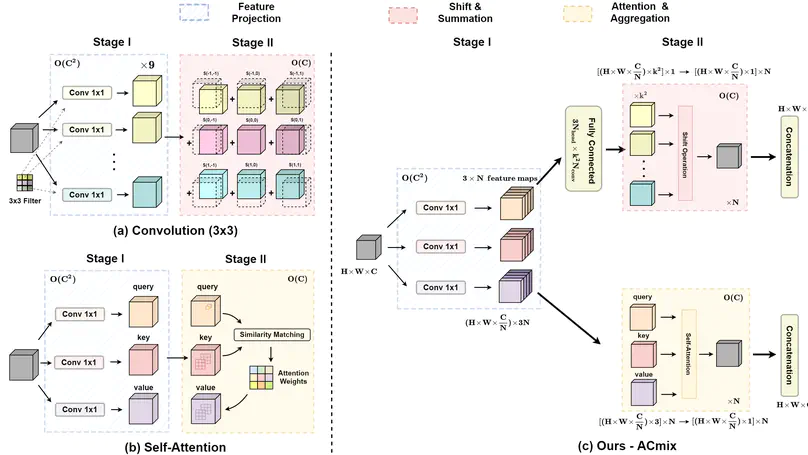
On the Integration of Self-Attention and Convolution.
In Computer Vision and Pattern Recognition (CVPR) 2022.
(2022).
Vision Transformer with Deformable Attention.
In Computer Vision and Pattern Recognition (CVPR) 2022.
(2022).
PLAM: A Plug-in Module for Flexible Graph Attention Learning.
In Neurocomputing 2022.
(2021).
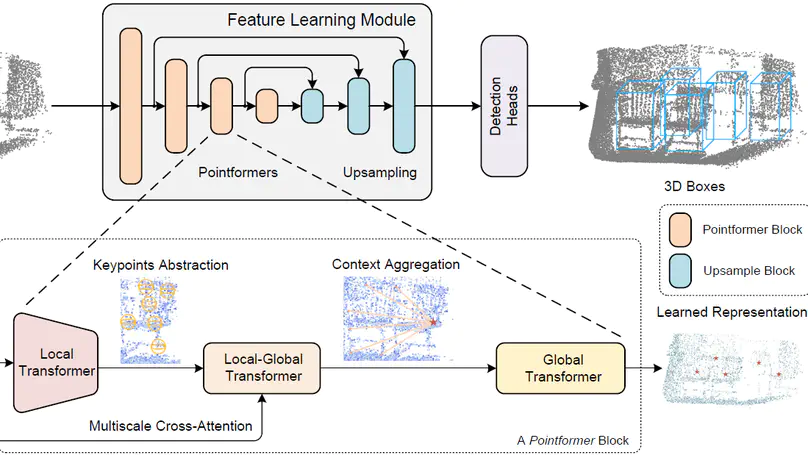
3D Object Detection with Pointformer.
In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2021.
(2021).
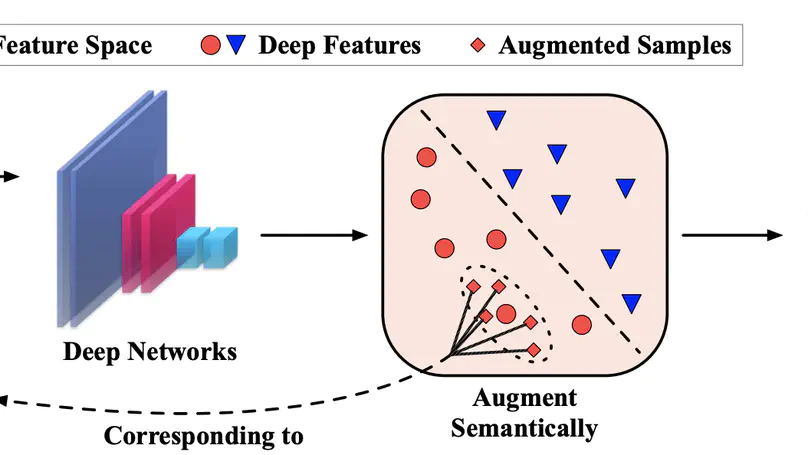
Regularizing Deep Networks with Semantic Data Augmentation.
In IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI) 2021.
(2019).
Implicit Semantic Data Augmentation for Deep Networks.
In Neural Information Processing Systems (NeurIPS) 2019.
Activities
Program Committee (PC) member of CICAI 2021
CAAI International Conference on Artificial Intelligence
Program Committee (PC) member of CICAI 2022
CAAI International Conference on Artificial Intelligence
Reviewer for CVPR, ICML, NeurIPS, ICLR, ICCV, ECCV, ICIG, IJRA, RiCO, Information Fusion
IEEE Computer Society / Elsevier
Contact
- pxr18@mails.tsinghua.edu.cn
- Room 616, Central Main building, Tsinghua University, Beijing 100084