Abstract
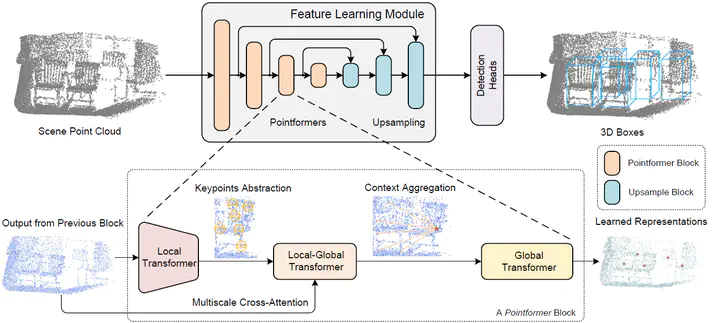
Feature learning for 3D object detection from point clouds is very challenging due to the irregularity of 3D point cloud data. In this paper, we propose Pointformer, a Transformer backbone designed for 3D point clouds to learn features effectively. Specifically, a Local Transformer module is employed to model interactions among points in a local region, which learns context-dependent region features at an object level. A Global Transformer is designed to learn context-aware representations at the scene level. To further capture the dependencies among multi-scale representations, we propose Local-Global Transformer to integrate local features with global features from higher resolution. In addition, we introduce an efficient coordinate refinement module to shift down-sampled points closer to object centroids, which improves object proposal generation. We use Pointformer as the backbone for state-of-theart object detection models and demonstrate significant improvements over original models on both indoor and outdoor datasets. Code and pre-trained models are available at https://github.com/Vladimir2506/Pointformer.
Xuran Pan
Ph.D. Student
My research interests lie in model architecuture design, graph neural network and 3D computer vision.