Abstract
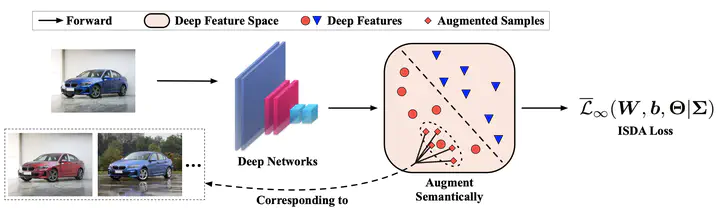
In this paper, we propose a novel implicit semantic data augmentation (ISDA) approach to complement traditional augmentation techniques like flipping, translation or rotation. Our work is motivated by the intriguing property that deep networks are surprisingly good at linearizing features, such that certain directions in the deep feature space correspond to meaningful semantic transformations, e.g., adding sunglasses or changing backgrounds. As a consequence, translating training samples along many semantic directions in the feature space can effectively augment the dataset to improve generalization. To implement this idea effectively and efficiently, we first perform an online estimate of the covariance matrix of deep features for each class, which captures the intra-class semantic variations. Then random vectors are drawn from a zero-mean normal distribution with the estimated covariance to augment the training data in that class. Importantly, instead of augmenting the samples explicitly, we can directly minimize an upper bound of the expected cross-entropy (CE) loss on the augmented training set, leading to a highly efficient algorithm. In fact, we show that the proposed ISDA amounts to minimizing a novel robust CE loss, which adds negligible extra computational cost to a normal training procedure. Although being simple, ISDA consistently improves the generalization performance of popular deep models (ResNets and DenseNets) on a variety of datasets, e.g., CIFAR-10, CIFAR-100 and ImageNet. Code for reproducing our results is available at https://github.com/blackfeatherwang/ISDA-for-Deep-Networks.
Xuran Pan
Ph.D. Student
My research interests lie in model architecuture design, graph neural network and 3D computer vision.